Exploring Shaders with Compiler Explorer
Note: if on mobile, consider reading this on a desktop/laptop, since CE is primarily a desktop experience at the moment
The Compiler Explorer (affectionately referred to as “Godbolt” after its creator’s namesake) is one of the best tools for compiler verification, disassembly exploration, collaboration, and learning around. Naturally, one evening while trying to diagnose a performance regression in a compute shader I was iterating on, I decided that CE ought to have shader support as well. Fast-forward three weekends later (one weekend spent at SIGGRAPH), I’m happy to say that HLSL is now a supported language in CE, with not just one, but two backend compilers: Microsoft’s DirectX Shader Compiler (DXC) and AMD’s Radeon GPU Analyzer (RGA).
In this post, I wanted to show roughly how the integration was done, what tradeoffs were made, and document existing limitations. My hope is that some of you readers may find it in you to lend a hand in supporting this awesome project in the future. At the very least, understanding what CE is doing behind the scenes will explain some of its quirks, in particular when using the RGA backend. On a practical level, this blog also has a few usage notes/tips to get the most out of the integration so you can use CE for your own shader exploration.
TL;DR Go try it out! Here’s a link to a sample to get you started (from MSFT’s DirectX wave intrinsics sample). Alternatively, for a much smaller example to iterate from, you can try this short pixel shader to start.
Developer Environment Setup
Building on top of CE is surprisingly straightforward, owing largely to its excellent documentation.
DXC is integrated primarily in hlsl.ts -
a relatively small class which extends BaseCompiler (where most of the heavy lifting is done).
RGA is integrated primarily in rga.ts.
Before we get into implementation details or usage, let’s first establish how you can get CE running locally
using your locally installed instances of DXC and/or RGA.
To set up a local development environment, you’ll need to add a file etc/config/hlsl.local.properties to
describe where CE can find DXC and RGA on your machine. Here’s my configuration as an example:
compilers=&dxc:&rga
group.dxc.compilers=dxc_default
compiler.dxc_default.exe=D:\\dxc-artifacts\\bin\dxc.exe
group.rga.compilers=rga_default
group.rga.compilerType=rga
compiler.rga_default.exe=C:\\Program Files\\GPUOpen\\Radeon GPU Analyzer\\rga.exe
compiler.rga_default.dxcPath=D:\\dxc-artifacts\\bin\\dxc.exe
defaultCompiler=rga
supportsBinary=false
compilerType=hlsl
Essentially, this config file says there are two compiler groups, dxc and rga, with just one
compiler for each group in this local configuration (dxc_default and rga_default respectively).
As I do most of my graphics programming work on Windows, I’m using Windows path conventions here, but
this works just as well on Linux and MacOS as well. Note the compilerType properties of the compiler,
which indicates which JS/TS class will govern the compiler’s usage. By default, the hlsl compiler
type is used (corresponds to HLSLCompiler), but the RGA compilers are all configured to use
RGACompiler instead. New compiler types are easy to create and register. Create a corresponding
class file in lib/compilers, ensure its imported and re-exported in lib/compilers/_all.js, and
ensure your compiler has the key getter implemented (this key is how we reference compiler types
in the property file seen above).
Finally, to run the CE locally (after doing an npm i to ensure all dependencies are installed),
I use the following command in pwsh:
npx cross-env NODE_ENV=DEV node -r esm -r ts-node/register .\app.js --language hlsl --debug
The various flags and args here enable debug logging, TS-to-JS transpilation, and crucially, only enables HLSL registered compilers (faster startup, leaner runtime footprint).
With luck, running the command above will start the runtime and a local instance of CE will be
accessible via localhost:10240. Note that the workflow above doesn’t support hot-reloading,
which only works on UNIX environments at the moment. My implementation strategy was to do most
of the iteration in a separate script, and only integrate it back into CE after I was satisfied
things were more or less working to have a fast edit-run-eval test loop.
Implementation Notes
By default, the only arguments supplied to DXC are -Zi and -Qembed_debug. This provides line
association directives in the emitted DXIL, which CE automagically picks up to provide the
familiar line highlighting as seen below.
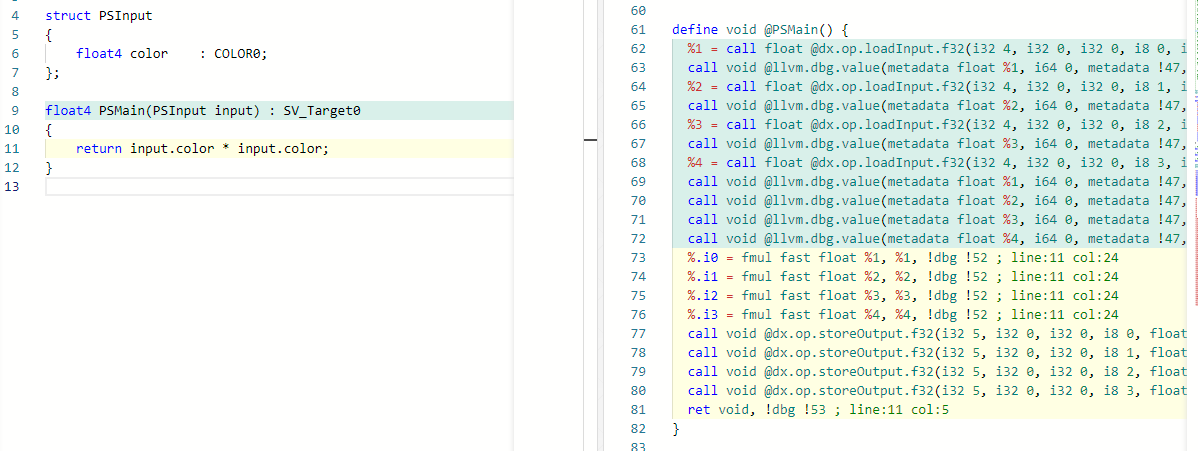
This of course poses a slight problem for compiling the default snippet, since DXC generally requires the target profile and entry point (except for DXR shaders) to compile. For now, the user must supply these arguments manually since it isn’t possible to infer the profile and target from the shader code alone (this may be improved in a future iteration of CE).
Integration of the RGA compiler was a fair bit trickier than DXC. First, the arguments from DXC to RGA are not in one-to-one correspondence. DXC is oriented around compiling individual shader modules (e.g. VS, PS, HS, AS, etc.) that are later linked together in a pipeline with DX12 commands. RGA however, requires the full pipeline state to do the final lowering from DXIL to assembly. Here’s an inexhaustive list of the reasons why pipeline state can affect the final assembly:
- Root signature indicates how descriptors are fetched, and whether they are static or volatile
- IA buffers may need format conversions on load
- Render target/depth-stencil outputs may need conversions on store
Invariably, there are likely many more subtle bits in the PSO state that could affect the disassembly, but these were the primary factors in my experimentation.
As such, the easiest pipeline/shader to compile with RGA is a compute shader, given that it
has effectively no fixed-function pipeline state, and only requires a root signature (which
may be embedded in the HLSL itself using the rootsignature attribute function).
A potential choice may have been to only support compute shaders in RGA. Another option would be to require the entire PSO specification (output formats, IA formats, etc.). I opted to do neither of these for the following reasons:
- As much as possible, it’d be useful to have a uniform argument interface between DXC and RGA. That is, for the most part, changing the compiler from DXC to RGA and back should “just work.”
- In the majority of cases, we don’t care about minute code changes in the shader’s prologue or epilogue to do data loads/stores. We can either infer what would happen, or check offline if really necessary.
- Exploration in CE should feel snappy and no-fuss. Needing to remember or copy-paste a root signature declaration with all the descriptors referenced in the shader felt anathema to this goal.
- Exposing RGA for “only compute shaders” is a bit surprising, and makes analyzing existing shaders a bit of a chore since conversion is needed for the entry point.
For these reasons, instead of compiling HLSL to DXIL and using the DX12
pathway in RGA, I used the HLSL to SPIR-V pathway with the -s vk-spv-txt-offline command switch.
Effectively, this does what we want, inferring a pipeline state given the entry point signature,
and filling in a “reasonable” root signature (effectively putting all descriptors in a descriptor
table from what I can tell). In this mode, we can compile DXIL to SPIR-V as a standalone shader
module, then feed that to RGA to produce the final ISA without any additional information - great!
The main downside of course is that there are differences in code generation when using DXIL as the intermediate language (IL) compared to SPIR-V. I’m hopeful that RGA will later release a similar DX12 offline mode to infer a default pipeline and root-signature, as in the Vulkan case.
Usage tips
By default, if you compile a shader in CE and observe the output, you should see something similar to this:
Already, this output is fairly useful for a number of things, however, it may seem a bit “bare” if you’re used to looking at DXIL output. That’s because comments are filtered by CE by default, and in the case of DXC, a lot of useful information is in the comments!
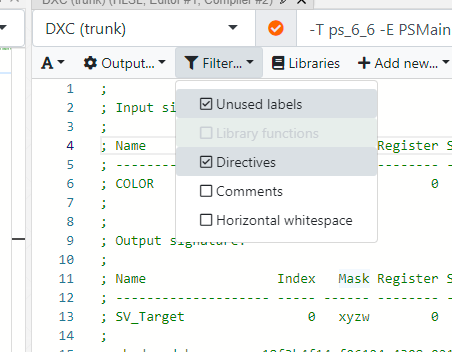
Unchecking the box above when working with DXC is generally a good idea because the comments show, among other things:
- Struct layouts and member offsets
- Shader hash
- Resource bindings
Here’s a small example with comments enabled:
Another thing worth remembering is that you can emit SPIR-V IL also using -spirv. Generally,
you would want to emit this in conjunction with the debug flag -fspv-debug=line to get line
directives (e.g. OpLine %6 23 12 might show up in the output, where %6 refers to the source,
23 the line, and 12 the column). However, CE doesn’t yet understand this style of line
annotation (to my knowledge) so SPIR-V line highlighting will have to wait for a future update.
When compiling with RGA, you’ll note that there are several more options for RGA than there are for DXC. For each installed version of RGA, there is a set of entries pairing that version with each installed version of DXC. This enables mix-and-matching DXC and RGA releases.
With comments filtered, compiling a shader snippet with RGA produces output as follows:
Note that unlike the DXIL snippets, RGA doesn’t emit line associations or PDB-like data, so we lose the highlighting. However, we get disassembly (aka the actual code that would run on your GPU, or at least something close to it) which is far more exciting! Like with DXIL, the comments that are filtered by default are hiding very useful information here:
The comments shown above are not emitted by RGA by default, but are embedded in the disassembly as
a “courtesy feature” in CE. Generally, this data is emitted as a separate file, requested using the
--livereg flag. Internally, RGA runs the shae.exe tool (included in the RGA package) to perform
live register analysis and emit the results. It is, however, fairly inconvenient to read this file in isolation,
so its contents are interleaved with the disassembly as comments instead. This is done by default -
nothing is needed to request it. To interpret the data, a helpful legend is shown at the top. The number
I tend to pay attention to is the second column.
; 14 | 10 | :^ :: :: :::: | label_0040: v_mbcnt_lo_u32_b32 v1, -1, 0
The second column indicates the total live register count at this point in the program. It’s useful to note where this column matches the total registers requested as the portion of the code where the live registers has swelled to its peak. The total VGPRs used and allocated are produced at the top.
Another thing to note is that by default, CE supplies gfx1030 as the ASIC to target (corresponds
to RDNA2 cards like the AMD Radeon RX 6800). You can change the target ASIC using a non-standard option
in the options field like so:
Here, the same shader as before is compiled but targeting a Vega GPU instead. If the default ASIC is used
(no --asic flag is supplied), the list of available ASICs is printed in the output window.
Active Bugs and Future Areas of Improvement
There is an issue currently where the assembly lines emitted by shae for the register lifetime
don’t actually match the assembly emitted by rga. This is because shae operates on instructions,
but labels themselves don’t constitute instructions. As a result, shae infers its own labels and
its output emitted as interspersed comments will go out-of-sync with the disassembly itself. This
is something that will be fixed upstream in a future RGA release.
Also, CE doesn’t yet have a mechanism to populate the user supplied options with defaults, in particular when the default source snippet is populated. This means that selecting HLSL as the source language for the first time will result in a failed compilation. This is something we may fix in an upcoming CE release.
CE does have a mechanism to display helpful tooltips when hovering over an instruction in the disassembly window. However, this metadata isn’t yet available for the AMD ISAs yet. A request has been made to gain access to this data in a form that’s easily parseable (lest we try to extract this data from the PDFs).
Last, it was mentioned before, but the limitation of needing to use SPIR-V IL prior to lowering to AMD’s ISA is a limitation of RGA not yet providing pipeline and RS inference in the DX12 mode. My hope is that the DX12 mode will gain similar functionality to the VK offline mode, and users will have a choice of IL when compiling with RGA.
Closing thoughts
I’d like to thank again the folks at both Compiler Explorer and AMD for providing these awesome tools for developers to use. If you’re reading this from the green team, do note that while I’m also a fan of the green team (and Nsight is awesome!), please do consider publishing an ISA and tools like RGA in the future, or you risk all future generations of graphics programmers having a great intuition about AMD shader assembly, and no other architecture!
HLSL support in CE is a work-in-progress, but please don’t hesitate to provide feedback, either as an issue filed to CE directly (@jeremyong is my github handle), or DM me on twitter (@m_ninepoints).